Status: in development, no public artifact yet. The source repo is private with no public demo or package (not on PyPI; no releases tagged). MTE describes itself as a research artifact with a working measurement harness, not a shipping product — its core question (does a structured pipeline beat one-shot LLM adaptation?) is explicitly unproven, though now measurable.
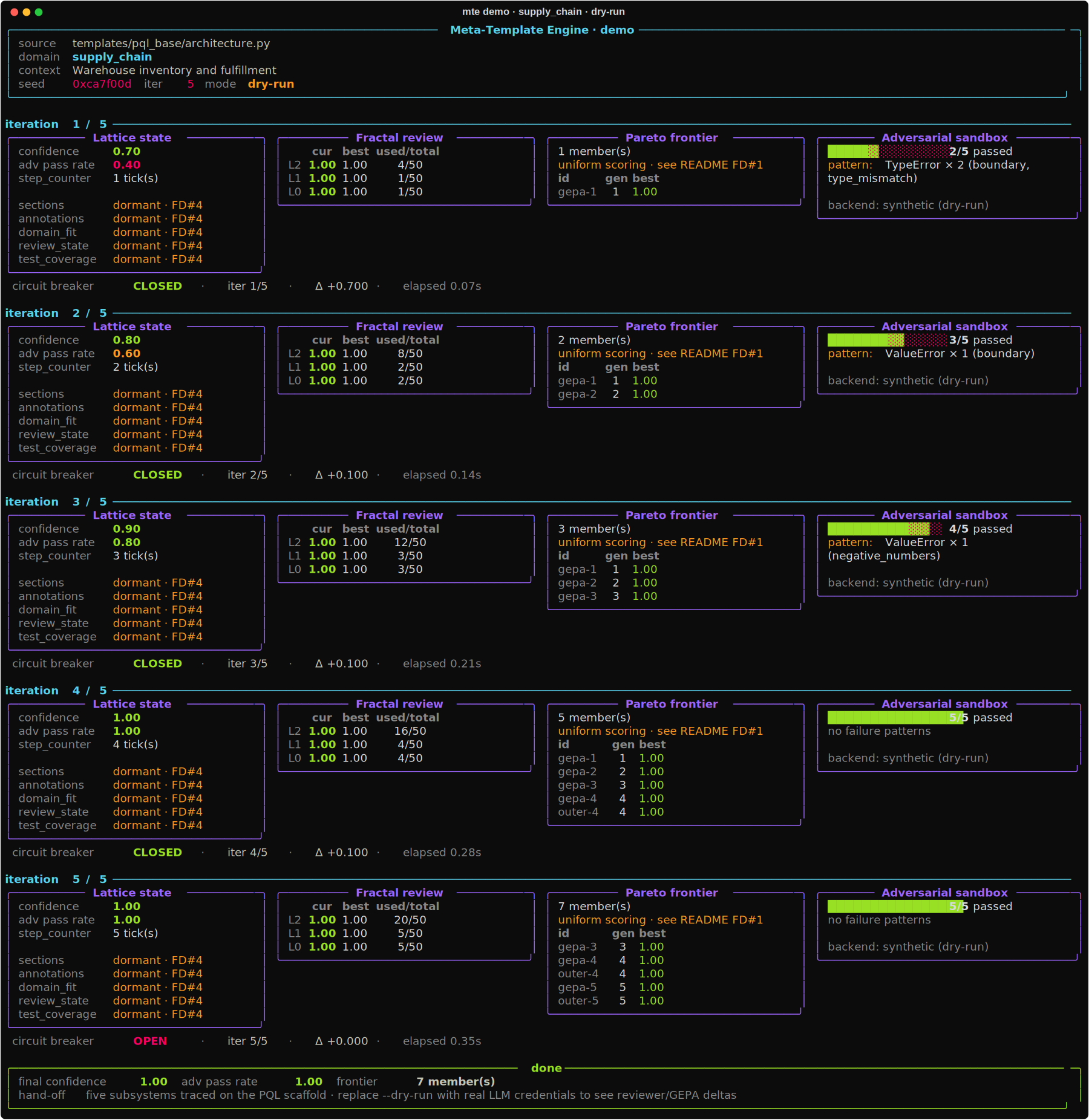
MTE adapts a reusable Python template to a target domain as a bounded, reviewable process — a monotonic loop reviewed at three scales (architecture / module / line), stressed by adversarial tests in a sandbox, and halted by a circuit breaker when it stops improving — instead of a single LLM prompt you can’t inspect.
What it does
- Adapts a template to a domain via a nested optimize/review loop that is monotonic in a join-semilattice (state can only improve).
- Reviews at three scales — architecture (L0), module (L1), and line (L2) — with per-level step budgets and gating thresholds.
- Stress-tests in a sandbox with adversarial, generated pytest cases (Docker with a subprocess fallback; a Go sandbox executor).
- Measures itself —
mte compareruns a one-shot baseline and the full pipeline over the same cases and reports the delta, so the benefit is testable rather than asserted.
Who it’s for
- Researchers of structured, lattice-based LLM orchestration, fractal review, and quiescence detection — the subsystems are real, tested, and composable.
- Anyone testing the premise — use
mte compare/mte evalto check whether pipeline-style adaptation beats one-shot on their own cases. - As a teaching codebase — eight cleanly separated subsystems, 380+ tests, property-based CRDT laws, a sandbox with a real threat model.
For a one-off code adaptation, the README recommends asking an LLM directly — that’s the baseline MTE measures itself against. MTE earns its overhead only with many adaptations of the same scaffold, a need for an audit trail, or interest in the orchestration itself.
Current State
Seven subsystems (lattice, templates, optimization, adversarial, review, quiescence, orchestrator) are wired end-to-end through MetaTemplateEngine.adapt — an eighth, training, ships as a separate data-export command — and reachable via four interfaces: CLI, REST API, an MCP server, and a web dashboard, over one service core. The suite is 380+ tests green on Python 3.12/3.13 at ~88% line coverage (CI gate ≥80%), ruff-clean, with the Go sandbox building and wheels passing twine check. The local Lefthook gate passes; hosted GitHub Actions is currently billing-paused.
What’s proven: the subsystems are correct and composable, the sandbox is hardened, and the pipeline runs to completion producing valid Python. What’s not proven yet: that the pipeline beats one-shot adaptation — the instrument to test it (mte compare) is built and plumbing-tested, but a live recorded verdict is the next milestone.
Source is private; architectural detail, a technical deep-dive, and the evaluation methodology are available on request via the contact page.
What’s Needed For This Entry To Tighten
- A public source repository linked via
githubUrl, and/or - A public demo URL or downloadable artifact that exercises the template-adaptation flow.
Verification
Full proof report → All claims, all projects →- In progress
Public source repository linked via githubUrl, or a public demo URL exercising the template-adaptation flow
Body — 'What's Needed For This Entry To Tighten'
Related work
-
beta
SUM — Verifiable Bidirectional Knowledge Distillation
Cryptographic provenance for AI knowledge transforms. Every transform — render, extract, compose, slider — emits a signed receipt anyone can verify offline. Six-regime compliance validators (EU AI Act, GDPR, HIPAA, SOC 2, ISO 27001, PCI DSS) and a layered sum verify --explain output landed in v0.7.0; current release is v0.8.1. Same bytes verify identically in Python, Node, and modern browsers.
-
in-development
AgentXAgent — Agent Team Arena
A platform for running competitive matches between AI agent teams. Configure teams, pit them against the same challenge, score outputs, build leaderboards.