An open-source observability backend for AI agents — debug what your agents are doing, evaluate their outputs against expected behavior, and catch quality drift before users do. Standards-native: ingests traces through vendor-neutral OTel GenAI + OpenInference (no proprietary wire format), makes every observability primitive queryable by any MCP client, and closes the eval-trace loop in a single schema — traces become dataset items become evaluator inputs become scores become monitor triggers become traces.
Three Deployment Shapes From One Codebase
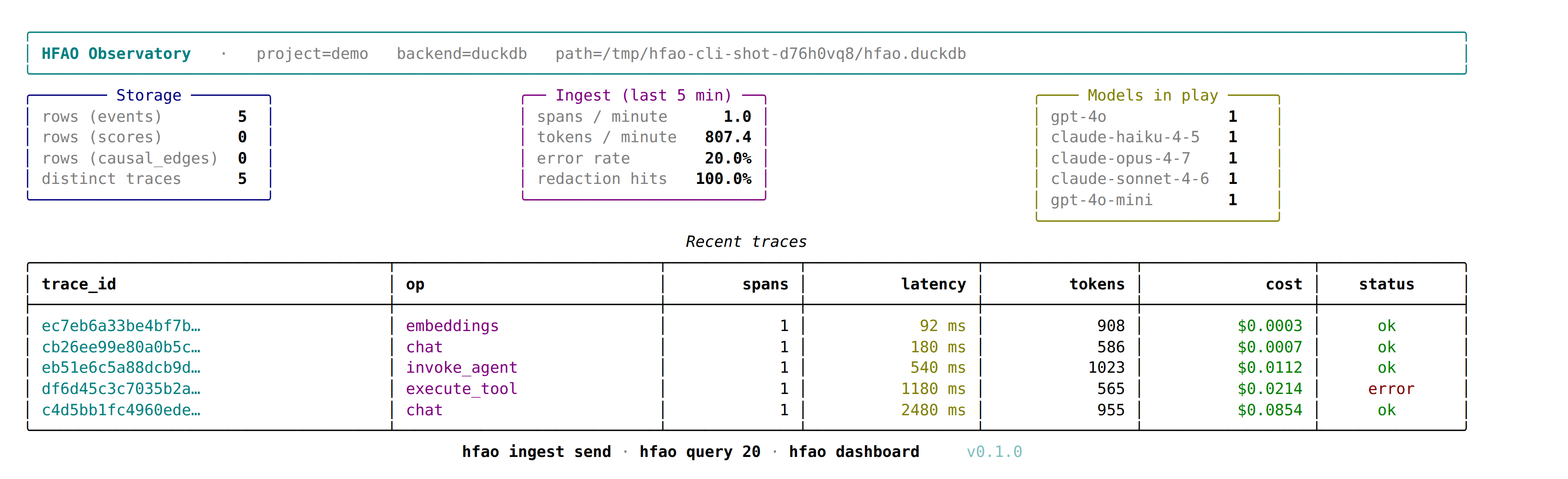
- Single-file HF Space — DuckDB embedded, the whole observatory running in one hosted notebook
- Docker Compose self-host — ClickHouse + Granian OTLP ingest, Redis Streams buffer
- Kubernetes enterprise — ClickHouse Cloud, Helm-deployed, multi-tenant
Three Pillars Commercial Competitors Can’t Easily Copy
- Standards-nativeness done right. OTel GenAI + OpenInference on ingest, full OTLP compatibility, no proprietary wire lock-in. Commercial vendors hedge this because it commoditizes their backend — HFAO has no reason to.
- MCP-native queryability. Traces, scores, causal edges, costs, prompts, datasets, experiments — all queryable by any MCP client. The observability backend agents debug themselves with.
- Closed eval-trace loop. One schema, one system. Not three SaaS products glued together.
Current State
- v1.0.0 (public-release packaging) on main — Phase-1 feature parity landed at v0.5.0 (196 passed / 6 skipped); v1.0.0 reaches the public-release-packaging milestone at 270 passed / 6 skipped (CHANGELOG), with Q-20 counterfactual replay, Q-18 anomaly surfacing, and Q-19 insight routing merged. Still a source-tree milestone — no pushed tag, no published PyPI package, and no hosted Space yet: the HF-Space / Docker publish workflows are placeholder stubs pending credentials.
- Storage plane — ClickHouse backend (§4.3 DDL, §6.1 Docker shape) and DuckDB backend with parity tests between the two
- Ingest plane — OTel GenAI + OpenInference normalizer (§5), Granian OTLP server (§7.1), PII redaction (§6.5), bounded buffer with memory + Redis Streams (§7.1–§7.3), body offload at 64 KiB (§6.6)
- MCP server — FastMCP Streamable HTTP at
:4319/mcp, the full §9.2 read surface plus a gatedscore_observationwrite (the queryability pillar) - Closed eval-trace loop — the computation plane (causal attribution, eval engine, cost rollups, monitors, retention, parquet export) operational end-to-end (§8)
- Stage 2 counterfactual replay — landed on main post-v0.5.0 (SPEC §16 Q-20): driver-pluggable replay across the three Tier-1 frameworks (LangGraph / OpenAI Agents SDK / Claude Agent SDK), tested with deterministic in-process stub agents (no live LLM calls)
- Proactive anomaly surfacing + insight routing — also post-v0.5.0 on main (SPEC §16 Q-18/Q-19): an
Insightschema +AnomalyEngine(rolling-mean Z-score, Western Electric control-chart rules, KS distribution drift, calibration drift, replay-verified) running alongside the monitor worker, plus a rule-basedInsightRoutermatching insights/alerts to role/user/agent subscriptions; surfaced in the cockpit Insights tab and via MCP - Cockpit UI — Gradio single-file cockpit (§10) with the analyst tabs; auth / RBAC / multi-tenancy (§13) and framework instrumentations (LangGraph, OpenAI-Agents, Claude-Agent, smolagents, …) shipped
- Spec discipline — SPEC.md locked at v1.0.0; every commit cites a spec section. Silent deviation is forbidden — ambiguity gets an Open Question in §16
Future Directions
- A published artifact — tagged release +
pip install hfaofrom PyPI (main is still a source-tree milestone with no pushed tag or package) - Deploy shapes hardening — Helm chart + docker-compose single-binary/Docker/K8s shapes are in flight (open PR #22), not yet on main
- DuckLake warm-tier auto-sync (§16 Q-13, targeted v1.1)
- Console UI (SvelteKit analyst surface, §11) — scaffold exists but explicitly deferred to v2.0 per §16 Q-11; not yet a real surface
Positioning
Parity with LangSmith / Langfuse / Phoenix / Braintrust / Weave / Helicone on tracing, datasets, evals, prompts, annotation, cost, and monitoring. Beyond them on the three pillars above.
Technical Stack
- License: Apache-2.0
- Language: Python (
hfaopackage) - Storage: ClickHouse (self-host + enterprise), DuckDB (single-file)
- Ingest: Granian OTLP server, Redis Streams buffer, PII redaction
- Wire: OpenTelemetry GenAI + OpenInference (OTLP-compatible)
- Deploy: single-file HF Space, Docker Compose, Kubernetes (Helm)
Verification
Full proof report → All claims, all projects →- Shipped
Storage plane (ClickHouse + DuckDB) with parity tests
tests/acceptance/test_ac_6_storage_*.py
- Shipped
Ingest plane (OTel GenAI + OpenInference normalizer, OTLP server, PII redaction, bounded buffer, body offload at 64 KiB)
tests/acceptance/test_ac_5_wire.py, test_ac_7_ingest.py
- Shipped
SPEC.md v1.0.0 locked; every commit cites a spec section
SPEC.md + commit message convention
- Shipped
MCP-native queryability across observability primitives (FastMCP Streamable HTTP, §9.2 read surface + gated score_observation write)
packages/hfao/mcp_server/ + tests/acceptance/test_ac_9_mcp.py (v0.5.0, SPEC §9)
- Shipped
Closed eval-trace loop (traces ↔ datasets ↔ scores ↔ monitors), with causal attribution, cost rollups, and retention
packages/hfao/compute/ + tests/acceptance/test_ac_8_causal.py, test_ac_8_eval.py, test_ac_8_cost_monitor.py (v0.5.0, SPEC §8)
- Shipped
Stage 2 counterfactual replay — driver-pluggable, Tier-1 frameworks (LangGraph / OpenAI Agents SDK / Claude Agent SDK)
packages/hfao/compute/causal/counterfactual.py + tests/acceptance/test_ac_8_counterfactual.py (post-v0.5.0 main, SPEC §16 Q-20)
- Shipped
Proactive anomaly surfacing (Insight schema + AnomalyEngine) and rule-based insight routing (subscriptions)
packages/hfao/compute/anomaly.py, schema/insights.py, compute/routing.py + tests/acceptance/test_ac_8_insights.py, test_ac_8_routing.py (post-v0.5.0 main, SPEC §16 Q-18/Q-19)
Repository README
HFAO — Hugging Face Agent Observatory
Open-source, standards-native agent observability. OpenTelemetry GenAI + OpenInference on ingest, MCP-native query surface, closed eval-trace loop in a single system.
![]()
![]()
![]()
HFAO is the observability backend agents debug themselves with. Point any framework — LangGraph, OpenAI Agents SDK, Claude Agent SDK, smolagents, CrewAI, AutoGen, DSPy, LlamaIndex, Haystack, raw openai / anthropic SDKs — at HFAO with one line, and get traces, scored evaluations, cost rollups, causal failure attribution, NL-defined monitors, and a Model Context Protocol surface every MCP client (Claude Desktop, Cursor, your own agent) can query.
import hfao
hfao.init(project="my-agent") # one line; auto-detects installed instrumentations
The three pillars
Commercial agent-observability vendors (LangSmith, Langfuse, Phoenix, Braintrust, Weave, Helicone) all do tracing + datasets + evals + monitoring. HFAO matches them on every line item. The reason to use HFAO is three things they cannot easily copy (see SPEC §1.1, Q-9 resolution):
1. Standards-nativeness done right
Every span HFAO ingests speaks OpenTelemetry GenAI (experimental semconv) and/or OpenInference. No proprietary wire format. No SDK lock-in. If your agent is already emitting OTLP, you're already done — point the OTLP exporter at http://localhost:4318/v1/traces and HFAO normalizes both attribute namespaces into a canonical schema at ingest.
Commercial vendors hedge on this because true standards-nativeness commoditizes their backend. HFAO has no reason to hedge.
2. MCP-native queryability
Every observability primitive HFAO stores — traces, observations, scores, causal edges, costs, prompts, datasets — is queryable by any MCP client. Boot up claude_desktop_config.json:
{
"mcpServers": {
"hfao": {
"url": "http://localhost:4319/mcp",
"headers": { "Authorization": "Bearer hfao_pat_..." }
}
}
}
…and Claude can now ask list_decisive_errors, get_causal_attribution, compare_runs, run_eval, get_cost_by over your live traces. Your agent can debug yesterday's failure the same way you can. The MCP surface is documented in SPEC §9.2.
3. Closed eval-trace loop
Traces → dataset items → evaluator inputs → scores → monitor triggers → traces, in one system with one schema, not glued across three SaaS products. A failed production trace becomes a golden-set item with one click in the cockpit (or one hfao CLI call). The next eval run scores against it. A regression flips a monitor. The monitor's alert links back to the trace it's protecting against.
What's in the box
Insight surfaces
| Surface | What it produces | Lives in |
|---|---|---|
| Causal attribution (§8.1) | Ranked decisive-error hypotheses per failing trace with confidence + evidence + per-edge replay_supported flag. Hypotheses, not verdicts. |
hfao.compute.causal |
| Eval engine (§8.2) | 8 built-in evaluators (exact_match, regex_match, json_schema_match, levenshtein_ratio, llm_judge, latency_p95, cost_per_call, tool_use_correct) + CI gates + judge calibration |
hfao.compute.eval |
| Cost rollups (§8.3) | Daily cost-per-(user, agent, model, prompt) pivot, refreshed every 60s | hfao.compute.cost |
| NL→SQL monitors (§8.4) | "Alert when error rate > 5% over 1h" → frozen SQL → threshold breach → webhook | hfao.compute.monitor |
| Cockpit (§10) | Single-file Gradio UI: Home, Traces, Trace detail, Live tail, Datasets, Prompts, Evals, Annotations, Monitors, Costs, Settings, Ask HFAO | apps/cockpit/cockpit.py |
| MCP server (§9) | FastMCP Streamable HTTP at :4319/mcp — every read tool + gated score_observation write |
hfao.mcp_server |
| Retention (§6.4) | Per-project hot-tier + body purge on a configurable cadence | hfao.compute.retention |
Deployment shapes
One codebase. Three shapes per SPEC §6.1:
| Shape | Hot tier | Control plane | Warm tier |
|---|---|---|---|
Single-file (HF Space) — pip install hfao && hfao up |
DuckDB embedded | SQLite | optional HF Buckets via DuckLake |
Docker Compose — docker compose up |
ClickHouse | Postgres | HF Buckets via DuckLake |
| Kubernetes (Helm chart) | ClickHouse Cloud | managed Postgres | HF Buckets / S3 / R2 |
Quickstart
pip install hfao # or `uv pip install hfao`
hfao up # → cockpit at :7860, OTLP at :4318, MCP at :4319/mcp
Then in your agent code:
import hfao
hfao.init(project="my-agent")
# Your existing agent code — LangGraph, OpenAI Agents SDK, Claude Agent SDK,
# smolagents, CrewAI, AutoGen, DSPy, LlamaIndex, Haystack, raw openai / anthropic.
# Every span auto-flows through the OpenInference / OTel GenAI instrumentor
# already installed for your framework.
The cockpit shows the trace within 2 seconds. The MCP server lets Claude/Cursor query it.
CI integration
hfao eval run goldens --evaluators exact_match,levenshtein_ratio \
--gate "exact_match>=0.9"
# Exits 1 if the gate fails — drop into any CI workflow.
Warm-tier export
hfao parquet export ./warm --from 2026-05-01 --to 2026-05-31 \
--hf-bucket f8n-ai/hfao-warm
Hourly partitions land at hf://buckets/f8n-ai/hfao-warm/hfao/v1/events/project_id=…/year=…/month=…/day=…/hour=…/part-0.parquet, readable from any DuckDB via the standard DuckLake catalog.
Retention
hfao retention set my-agent --hot-days 30 --bodies-days 90
hfao retention run # one-shot pass; or run as a daemon worker
Framework support
Tier 1 — full acceptance coverage (replay-supported per §12.2): LangGraph · OpenAI Agents SDK · Claude Agent SDK · smolagents · raw LLM SDKs (openai · anthropic · mistral · groq · bedrock · vertex · google-genai)
Tier 2 — generic harness path (counterfactual replay unsupported per §12.2): CrewAI · AutoGen · DSPy · LlamaIndex · Haystack · Pydantic AI · Google ADK · AWS Strands · LiteLLM · MCP-as-instrumentation
Tier 2 frameworks land via a shared harness — community PRs adding a new instrumentor extend the harness's catalog rather than writing per-framework AC tests.
Architecture
agent code ─OTLP/HTTP→ Granian server (:4318) ─→ normalize ─→ Redis Streams
│
▼
DuckDB (single-binary) / ClickHouse (Docker / K8s) ←──── batched writer
│ │ │
│ │ ▼
▼ ▼ on-demand Parquet
HF Buckets warm tier compute plane (`hfao parquet export`,
(DuckLake catalog) ┌──────────────────┐ auto-sync in v1.1)
│ causal attribution (§8.1)
│ eval engine (§8.2)
│ cost rollups (§8.3)
│ monitor engine (§8.4)
│ retention (§6.4)
└──────────────────┘
│
▼
cockpit (Gradio :7860) ──────────────────────────────────────────────── MCP (:4319/mcp)
Storage is protocol-abstracted (§6.2): every backend implements one StorageBackend protocol and no SQL is allowed outside packages/hfao/storage/. Swapping DuckDB → ClickHouse is a config flip, not a code change. The cockpit, MCP server, eval engine, monitor engine, retention worker all depend on the protocol, never on a concrete backend.
Status
This repository is built against SPEC.md v1.0.0. Implementation is on schedule:
| Milestone | Tag | What's done |
|---|---|---|
| M1 — Walking skeleton | v0.1.0 |
✅ OTLP ingest, DuckDB hot tier, cockpit, MCP list_traces/get_trace, single-binary deploy |
| M2 — Phase 1 feature parity + Experiment primitive | v0.5.0 |
✅ Causal attribution · eval engine · cost rollups · monitors · retention · Parquet export · experiment runner with paired statistics. The closed eval-trace loop is operational end-to-end. |
| M3 — Phase 2 differentiation | v1.0.0 |
⏳ Counterfactual replay (Stage 2), Helm chart, marquee examples |
The §16 Open Questions ledger is the source of truth for every deviation from the original plan. Treat that file as the audit trail for "why does v1 look like this?"
License
Apache-2.0. See LICENSE.
The full design rationale lives in SPEC.md. Contributor onboarding: read CLAUDE.md first — the "no spec deviation without a §16 entry" rule is the single most important constraint in this codebase.
Related work
-
beta
SUM — Verifiable Bidirectional Knowledge Distillation
Cryptographic provenance for AI knowledge transforms. Every transform — render, extract, compose, slider — emits a signed receipt anyone can verify offline. Six-regime compliance validators (EU AI Act, GDPR, HIPAA, SOC 2, ISO 27001, PCI DSS) and a layered sum verify --explain output landed in v0.7.0; current release is v0.8.1. Same bytes verify identically in Python, Node, and modern browsers.
-
in-development
Memory Mind Mesh — Living Memory for AI
AI memory that learns from feedback. Responses get more accurate and more concise the more they're used — instead of decaying as the model drifts. Hybrid static + adaptive store.