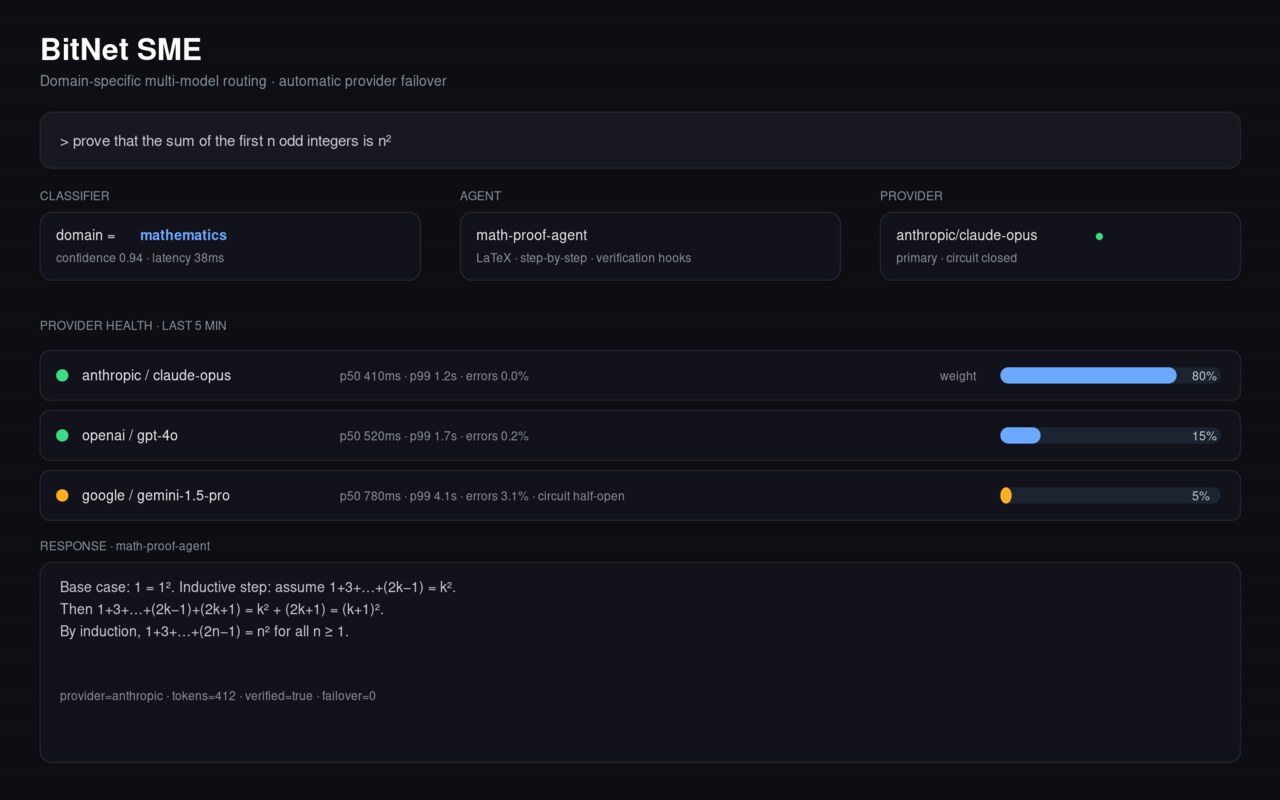
A FastAPI service that serves specialized domain experts as one typed contract, built on DSPy 3.2. Each domain is a real dspy.Module; a router dispatches the question; LiteLLM handles provider routing; MLflow traces every run; and a dspy.Evaluate harness drives MIPROv2/GEPA prompt optimization. A 1-bit bitnet.cpp local provider is an optional fallback for offline / PII / air-gapped workloads. (Renamed from “BitNet SME Expert v2.0” — v2 was string stubs with no DSPy or BitNet code; v3 rebuilt the expert layer for real.)
What runs today
- Per-domain
dspy.Moduleexperts underapp/dspy_modules/— a math module (dspy.ReActover seven SymPy tools plus a deterministic arithmetic fast-path), a code module, and a general module (dspy.ChainOfThought, with an opt-indspy.ReActhybrid-RAG path over LanceDB with a BGE-family embedder + bge-reranker-v2-m3 whenRAG_ENABLED). A router module dispatches by domain. - Provider routing via LiteLLM — per-role LM specs (router / math / code / general) with
DSPY_LM_<ROLE>env overrides, so any provider (or the localbitnet.cppserver) can back any role. - MLflow tracing — autolog wired into the DSPy configuration.
- An optimization loop with an enforced eval gate —
scripts/optimize.pycompiles each domain with MIPROv2/GEPA;scripts/run_eval.pyrunsdspy.Evaluateper domain against per-domain thresholds.eval.ymlruns on every pull request tomain(a required status check viabranch-protection.yml), posting a per-domain score table with Wilson 95% CIs to the PR. A committed receipt (eval/receipts/math-miprov2.json) records a real MIPROv2 win on math: baseline 0.62 → 0.80 (+0.18) on a held-out split (50-row train / 50-row holdout per domain). - An MCP server —
app/mcp_server.py(officialmcpSDK,dspy-sme-mcpconsole script) exposes the math/code/general experts as Model Context Protocol tools over the same DSPy programs. - One typed FastAPI contract with the usual plumbing (Pydantic v2 schemas, SlowAPI rate limiting, CORS, Docker multi-stage build).
The air-gapped thesis
The defensible niche isn’t “we run BitNet” — the model is open-weight. It’s the corpus + a distillation/eval pipeline packaged to run fully offline on a CPU, for sovereignty/regulated buyers (legal, finance, defense, HIPAA) where the data never leaves the enclave. Paired with SUM (verifiable, citeable answers offline) and InfiniteContext (on-device retrieval without a cloud vector DB), it forms an offline expert stack that cloud incumbents structurally can’t ship.
What’s next (honest gaps)
- Eval receipts beyond math. The committed receipt covers the math domain (+0.18 MIPROv2 win on a 50-row held-out split); code and general have train/holdout gold sets but no committed baseline-vs-compiled win yet. Scaling the splits past 50/domain would tighten the Wilson CIs further.
- A measured BitNet receipt.
scripts/bitnet_demo.shmeasures real tok/s through the DSPy path and writes a datedeval/receipts/bitnet-<date>.txt, but it needs real hardware to run, so no measured figure is committed yet (the README deliberately ships none until the demo produces one). - A published/installable artifact. No GitHub release, package, or hosted demo yet — the prerequisite for promoting this past in-development.
Technical Stack
- Framework: Python ≥3.12 (
uv-managed) / FastAPI / Pydantic v2 - Optimization: DSPy 3.2 (
dspy.Module/dspy.ReAct/dspy.ChainOfThought,dspy.Evaluate, MIPROv2 / GEPA) - Provider routing: LiteLLM (per-role LM specs, env overrides)
- Tracing: MLflow autolog
- Retrieval (opt-in): LanceDB + a BGE-family embedder & bge-reranker-v2-m3 (hybrid RAG) for the general expert
- Local/offline:
bitnet.cpp1-bit server (OpenAI-compatible) - Domain tools: SymPy (math)
- Ops: Docker multi-stage build, Makefile, pytest, ruff
Repository README
dspy-sme-expert
DSPy-powered multi-expert SME system. A FastAPI service that routes
questions to domain-specialist dspy.Modules (math, code, general), with
LiteLLM provider routing, MLflow tracing, agentic hybrid RAG, and a
dspy.Evaluate harness driving MIPROv2 / GEPA optimization.
![]()
Substrate-agnostic by design
The specialization layer (DSPy programs + optional ReAct tools + optional
RAG + compiled prompts) is the constant. The model running underneath is a
config flip. Four substrates are first-class and can be mixed per role via
DSPY_LM_<ROLE> env vars:
| Substrate | Best when | Setup |
|---|---|---|
| HF Inference Providers | Frontier-grade open weights, zero ops | env vars only |
| Modal-hosted vLLM | Specific HF base on a specific GPU, scales to zero | modal deploy scripts/modal_serve.py |
| BitNet (local) | Laptop latency, sovereign data, $0 marginal cost | make bitnet-setup && make bitnet-serve |
| Frontier APIs | Max capability, no time to specialize | env vars only |
See docs/deployment-modal-hf.md for the full playbook with copy-paste recipes for each. The hybrid sweet spot for most teams: Router + General on a frontier API, Math + Code on a fine-tuned Modal-hosted base or BitNet.
What changed in v3.0
| Layer | v2 | v3 |
|---|---|---|
| Expert layer | Hardcoded canned-string stubs | dspy.Modules with typed signatures |
| Math | Regex routing + sympy fallback | dspy.ReAct(SolveMathProblem, tools=[sympy_*]) + deterministic fast-path |
| Code | Pattern matching + template strings | dspy.ChainOfThought(GenerateCode) |
| General | Random pick from canned responses | dspy.ChainOfThought(AnswerGeneralQuestion) |
| Routing | Hardcoded keyword if/elif |
RouterProgram (dspy.ChainOfThought) — optimizable |
| Multi-provider | Three SDKs imported, none called | dspy.LM over LiteLLM, per-role model selection |
| Optimization | n/a | MIPROv2 / GEPA via scripts/optimize.py, persisted to compiled/ |
| Observability | structlog + Prometheus | + mlflow.dspy.autolog() (OTel traces of module calls) |
| Package mgmt | requirements.txt + pyproject.toml (drift) |
uv + single pyproject.toml + uv.lock |
| Python | 3.9+ | 3.12+ |
| Pydantic | mixed v1/v2 | v2 throughout |
| JWT | python-jose (unmaintained) |
PyJWT |
| BitNet | name only | optional bitnet.cpp provider via OpenAI-compatible llama-server |
Architecture
graph TB
A[Client] --> B[FastAPI<br/>app.main]
B --> C[Auth + Logging + Rate-limit<br/>middleware]
C --> D[ExpertService]
D --> E[RouterProgram<br/>dspy.ChainOfThought]
E --> F{domain}
F -->|math| G[MathExpert<br/>dspy.ReAct + sympy tools]
F -->|code| H[CodeExpert<br/>dspy.ChainOfThought]
F -->|general| I[GeneralExpert<br/>dspy.ChainOfThought]
G --> J[dspy.LM via LiteLLM]
H --> J
I --> J
J -->|OpenAI/Anthropic/Gemini| K[Provider APIs]
J -->|local bitnet.cpp| L[llama-server :8080]
J -.->|autolog| M[MLflow<br/>traces + optimizer runs]
Quickstart
Naming: the GitHub repository is
bitnet-sme-expert(a historical name from the v2 era); the Python package, CLI, and import path are alldspy-sme-expert/dspy_sme. Same project — the repo just wasn't renamed.
# 0. Clone.
git clone https://github.com/OtotaO/bitnet-sme-expert.git
cd bitnet-sme-expert
# 1. Get uv if you don't already have it.
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. Install everything.
uv sync --all-extras
# 3. Configure providers.
cp .env.example .env
$EDITOR .env # at minimum set OPENAI_API_KEY (or override DSPY_LM_*)
# 4. Run.
uv run uvicorn app.main:app --reload
# -> http://localhost:8000/docs
One-shot query without spinning up the server:
uv run dspy-sme query "What is the derivative of x^3 + 2x?" --domain math
Optimization loop
# Baseline + MIPROv2 light compile (saves to compiled/math.json)
make optimize-math
# Or use GEPA for reflection-based prompt evolution
make optimize-math-gepa
MIPROv2 (auto=light) is a solid default for our small (~50-example) train sets
and is what produced the committed +0.18 math win. For instruction-heavy gains,
GEPA (reflective prompt evolution, an ICLR 2026 result reported to beat
MIPROv2 by >10% on such tasks) is the stronger lever and is worth preferring as
the gold sets grow — especially if you have its metric return short natural-language
feedback, which is where its edge comes from.
Compiled programs are loaded automatically at startup. To re-run the eval harness against the compiled programs:
RUN_EVAL=1 uv run pytest tests/eval -v -s
Eval gate & receipts
The gold sets ship as a committed train/holdout split so a reported score
can't be an overfit-to-the-eval-set artifact (tests/eval/loader.py):
| Domain | Train | Holdout | Pass threshold (holdout) |
|---|---|---|---|
| math | 50 | 50 | 0.60 |
| code | 50 | 50 | 0.60 |
| general | 50 | 50 | 0.70 |
scripts/optimize.py compiles on train and scores on holdout, writing a
dated receipt to eval/receipts/<domain>-<optimizer>.json (baseline, compiled,
delta, LM, split sizes). The Eval workflow runs scripts/run_eval.py against
the holdout set on every PR to main as a required check (see
.github/workflows/eval.yml). Eval is pinned to temperature=0 so scores are
reproducible.
Committed receipts (openai/gpt-4o-mini, temp 0, 2026-06-04)
Baseline holdout scores (no compiled program loaded), on the 50-item holdouts:
| Domain | N (holdout) | Score | Threshold | Pass |
|---|---|---|---|---|
| math | 50 | 0.62 | 0.60 | ✅ |
| code | 50 | 1.00 | 0.60 | ✅ |
| general | 50 | 1.00 | 0.70 | ✅ |
Math sits just above its threshold on the harder 50-item set (it scored 0.73 on the earlier easy 15), so the gate genuinely bites. Code and general saturate the substring metrics at 1.00 — those metrics are lenient proxies (see the eval follow-ups issue), not evidence the models are perfect.
MIPROv2 (auto=light) compile — math (eval/receipts/math-miprov2.json):
| Domain | Baseline | Compiled | Delta |
|---|---|---|---|
| math | 0.62 | 0.80 | +0.18 |
A real, reproducible win on the held-out set (50 train / 50 holdout,
gpt-4o-mini, temp 0). Worth noting why this is trustworthy: the first
committed receipt for this domain was a −0.13 on the earlier 15-item holdout
— MIPROv2 looked like it hurt. That was a small-sample artifact; on the larger
gold set the optimizer genuinely lifts math from 0.62 to 0.80. We kept the
negative receipt while it stood (project policy: never massage a non-positive
delta) and replaced it only when a bigger, honest measurement superseded it.
code and general were not compiled: their substring metrics already saturate
the holdout at 1.00, leaving no measurable headroom until those metrics are
tightened.
Auto-generated receipt table
The table below is regenerated by scripts/write_eval_receipt.py from the JSON
receipts under eval/receipts/. Do not hand-edit between the markers — run
make eval-receipt (or the script directly) after a new receipt lands. Until a
new receipt is produced, the block shows a clearly-labelled placeholder.
Generated by scripts/write_eval_receipt.py on 2026-06-06 from eval/receipts/. Numbers are copied verbatim from the JSON receipts; this table never invents values.
| Domain | Optimizer | LM | Baseline | Optimized | Delta | N (holdout) | Receipt |
|---|---|---|---|---|---|---|---|
| math | miprov2 | openai/gpt-4o-mini | 0.62 | 0.80 | 0.18 | 50 | math-miprov2.json |
Picking a substrate
The full comparison + copy-paste recipes live in docs/deployment-modal-hf.md. The 30-second version:
HF Inference Providers — zero ops, frontier open weights, billed via HF:
export HF_TOKEN=hf_...
export DSPY_LM_GENERAL="huggingface/auto/meta-llama/Llama-3.3-70B-Instruct"
Modal-hosted vLLM — specific HF base on a specific GPU, scales to zero:
modal deploy scripts/modal_serve.py # one shot
export DSPY_LM_CODE="openai/Qwen/Qwen2.5-Coder-32B-Instruct"
export DSPY_LM_CODE_API_BASE="https://<workspace>--dspy-sme-vllm-serve.modal.run/v1"
# API_KEY_ENV names the env var holding the key (app/llm.py reads it indirectly):
export DSPY_LM_CODE_API_KEY_ENV="MODAL_VLLM_KEY"
export MODAL_VLLM_KEY="$YOUR_MODAL_KEY"
Modal-hosted fine-tuning — Unsloth + TRL on H100, adapter pushed to HF Hub:
modal run scripts/modal_finetune.py::train \
--base-model meta-llama/Llama-3.3-70B-Instruct \
--dataset-repo your-org/your-domain-sft \
--output-repo your-org/llama-3.3-70b-domain-lora
BitNet (local) — laptop latency, sovereign, $0 marginal cost. See the detailed section below.
Optional: local inference with bitnet.cpp
bitnet.cpp ships an OpenAI-compatible llama-server (built during its
setup_env.py cmake step). Wire it up as any other dspy.LM:
# One-time: clone, build, download the b1.58 2B 4T model (~3 GB)
make bitnet-setup
# Serve it locally on :8080
make bitnet-serve
# Tell DSPy to use it for the math expert
export DSPY_LM_MATH="openai/bitnet"
export DSPY_LM_MATH_API_BASE="http://localhost:8080/v1"
export DSPY_LM_MATH_API_KEY_ENV="BITNET_DUMMY_KEY"
export BITNET_DUMMY_KEY="local"
The 2B-4T BitNet model is a useful local fallback for PII-sensitive or offline workloads. Its real edge is footprint and energy, not raw quality: ~0.4 GB non-embedding memory and ~10× lower energy than comparable fp16 small models, at competitive-but-not-superior ~2B quality (it trails Qwen2.5-1.5B on MMLU). Throughput is hardware-dependent — measure it on your own box:
make bitnet-demo # sends a fixed prompt through the DSPy path, prints
# measured tok/s, writes eval/receipts/bitnet-<date>.txt
(Microsoft's model card reports ~29 ms/token CPU decode latency for the
b1.58-2B-4T model via bitnet.cpp — the transformers path gets none of that
speedup. The widely-quoted "5-7 tok/s" figure is the 100B BitNet, not this
2B model. This repo ships no measured figure of its own until make bitnet-demo
produces one. If you want a larger local ecosystem, a Q4 Qwen3-1.7B / Gemma-3-1B
on llama.cpp drops into the same openai/-compatible provider slot.)
Observability
Set MLFLOW_TRACKING_URI (or run docker compose up mlflow) to enable
mlflow.dspy.autolog(). Every module call at serve/eval time produces an
OpenTelemetry span you can inspect in the MLflow UI.
When MLFLOW_TRACKING_URI is set, scripts/optimize.py also logs each optimizer
run as an MLflow run — params plus the baseline/optimized/delta metrics, with the
committed receipt attached as an artifact — so compiled programs are A/B-comparable
in the UI. The committed receipts under eval/receipts/ remain the source of
truth regardless of whether MLflow is configured.
API
| Method | Path | Description |
|---|---|---|
| GET | /health, /health/live, /health/ready |
Probes |
| GET | /metrics |
Prometheus scrape endpoint |
| GET | /api/v1/experts |
List registered experts |
| POST | /api/v1/query |
Route a question (auto or domain=...) |
| POST | /api/v1/collaborate |
Fan out to several experts in parallel |
| POST | /api/v1/feedback |
Submit feedback on a previous query (logged, not yet persisted) |
| POST | /api/v1/fine-tune |
Kick off a fine-tuning job (experimental; admin-gated) |
| GET | /api/v1/training/status/{job_id} |
Fine-tuning job status (experimental) |
| GET | /api/v1/training/jobs |
List fine-tuning jobs (experimental) |
| POST | /cache/clear |
Clear the response cache (admin-gated) |
| GET | /cache/stats |
Response-cache statistics |
Interactive docs at /docs (Swagger) and /redoc.
MCP server
The experts are also exposed over the Model Context Protocol
so any MCP host (Claude Desktop, IDEs, agent runtimes) can route questions to
them. Built on the official mcp SDK; install the extra and run over stdio:
uv sync --extra mcp
uv run dspy-sme-mcp # serves over stdio
Tools: ask_expert(question, domain?) (auto-routes when domain is omitted)
and list_experts(). The same DSPy programs back both the HTTP API and the MCP
tools (shared app/bootstrap.py).
Project layout
app/
├── main.py FastAPI app + lifespan
├── cli.py `dspy-sme` console script
├── mcp_server.py `dspy-sme-mcp` — MCP server over the experts ([mcp] extra)
├── bootstrap.py Shared expert-service construction (app + MCP)
├── auth.py Per-route auth dependencies (require_role)
├── limiter.py Shared SlowAPI limiter
├── llm.py DSPy LM configuration (LiteLLM + MLflow)
├── config.py Settings (Pydantic v2)
├── observability.py JSON logging + Prometheus metrics
├── dspy_modules/ Signatures + Modules (the model code)
│ ├── signatures.py
│ ├── router.py
│ ├── math_module.py
│ ├── code_module.py
│ └── general_module.py
├── experts/ Thin wrappers exposing the API contract (see experts/README.md)
├── services/ ExpertService (routing, collaborate, fine-tuning)
├── api/endpoints/ FastAPI routes (core + fine_tuning)
├── middleware/ CORS, logging, errors (auth is per-route, see auth.py)
├── schemas/ Pydantic v2 request/response models
├── models/ Abstract expert base, training + feedback ORM models
├── retrieval/ Optional hybrid RAG (LanceDB + BGE), [rag] extra
├── core/ Exceptions and shared internals
├── database.py Engine + session bootstrap
└── ...
scripts/
├── optimize.py MIPROv2 / GEPA compile pipeline (writes eval/receipts/)
├── run_eval.py Holdout eval runner (the CI gate)
├── bitnet_setup.sh Build bitnet.cpp + pull the model
├── bitnet_serve.sh Run the llama-server
└── bitnet_demo.sh Measure local tok/s (writes a receipt)
tests/
├── test_experts.py Wiring smoke tests (no LM)
└── eval/ loader (train/holdout split) + gold sets + metrics (RUN_EVAL=1)
eval/receipts/ Committed optimizer/throughput receipts
compiled/ Optimized programs land here (gitignored)
Docs
AGENTS.md— orientation for AI/agent sessions: invariants, dev loop, where open work is tracked. Read this first if you're picking up the project.docs/strategy.md— strategy, goals, outcomes, and honest current state.docs/specialization.md— the BitNet + DSPy specialization playbook.docs/deployment-modal-hf.md— deployment substrates (HF Providers, Modal vLLM/SFT, local BitNet).app/experts/README.md— how to add a new domain expert end to end.CONTRIBUTING.md— dev loop, the eval/optimize cycle, and the receipts policy.
Development
make install # uv sync --all-extras
make test # unit tests (no LM)
make test-eval # eval tests (requires provider keys, RUN_EVAL=1)
make lint # ruff + mypy
make format # ruff format + fix
make build # docker build (production target)
License
MIT. See LICENSE.
Related work
-
in-development
AgentXAgent — Agent Team Arena
A platform for running competitive matches between AI agent teams. Configure teams, pit them against the same challenge, score outputs, build leaderboards.
-
beta
SUM — Verifiable Bidirectional Knowledge Distillation
Cryptographic provenance for AI knowledge transforms. Every transform — render, extract, compose, slider — emits a signed receipt anyone can verify offline. Six-regime compliance validators (EU AI Act, GDPR, HIPAA, SOC 2, ISO 27001, PCI DSS) and a layered sum verify --explain output landed in v0.7.0; current release is v0.8.1. Same bytes verify identically in Python, Node, and modern browsers.
-
in-development
InfiniteContext — Tiered Memory for AI
An extensible memory layer that pushes past model context limits: a hierarchical bucket store with exact-flat persistence and approximate (HNSW) retrieval at scale, automatic categorization, multi-level summarization, and pluggable storage tiers from local disk to cloud. Public, MIT-licensed TypeScript library + CLI.